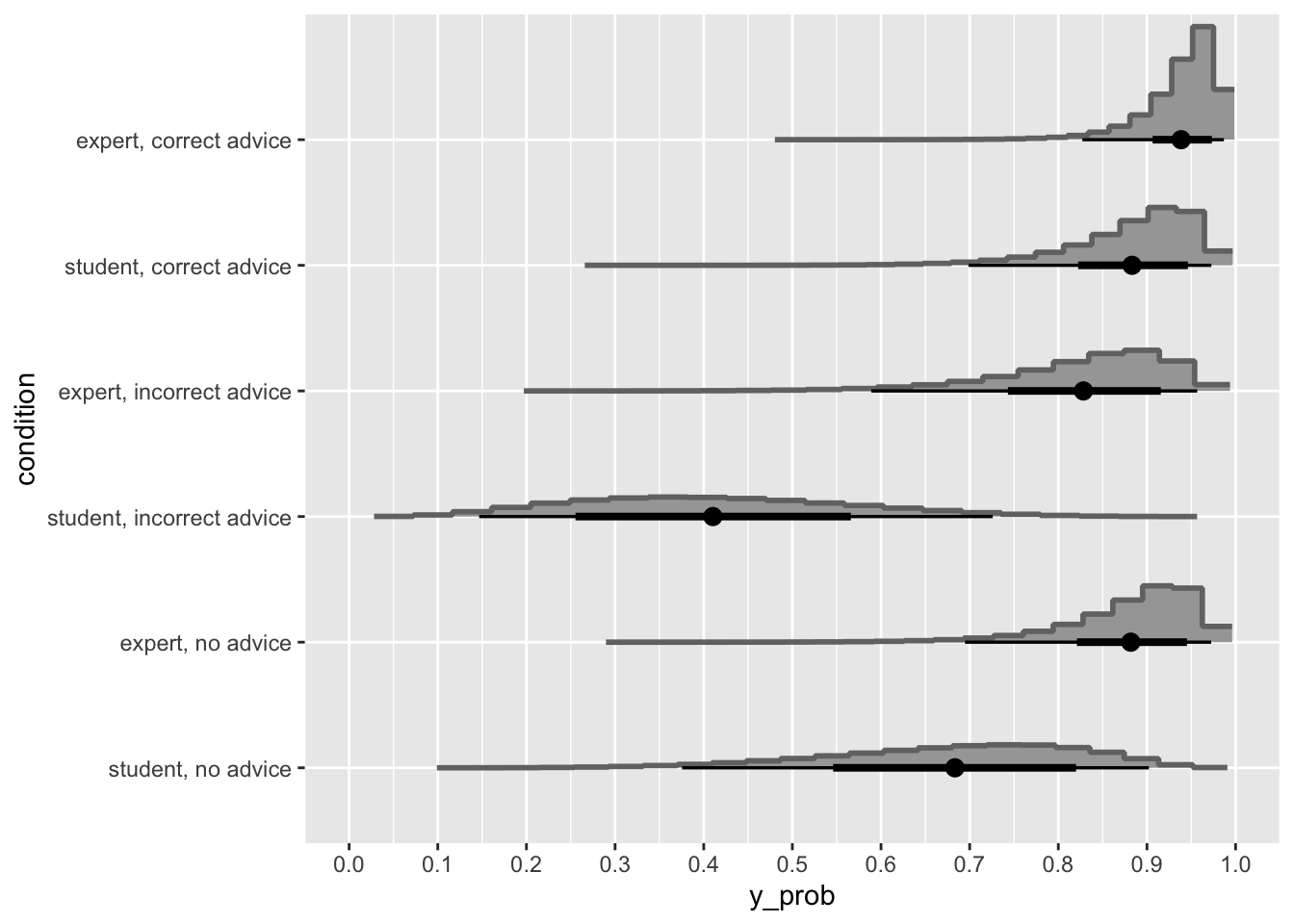
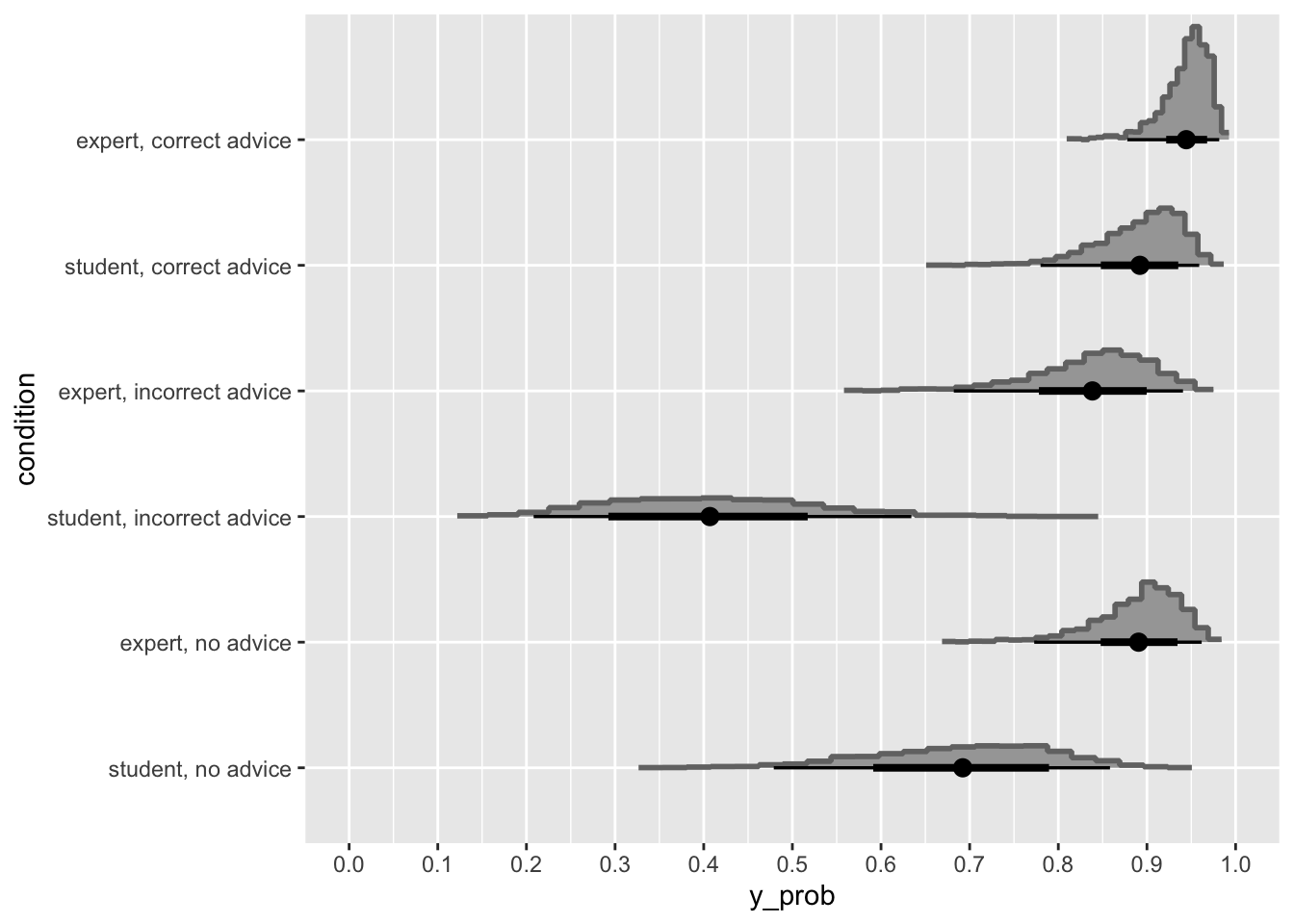
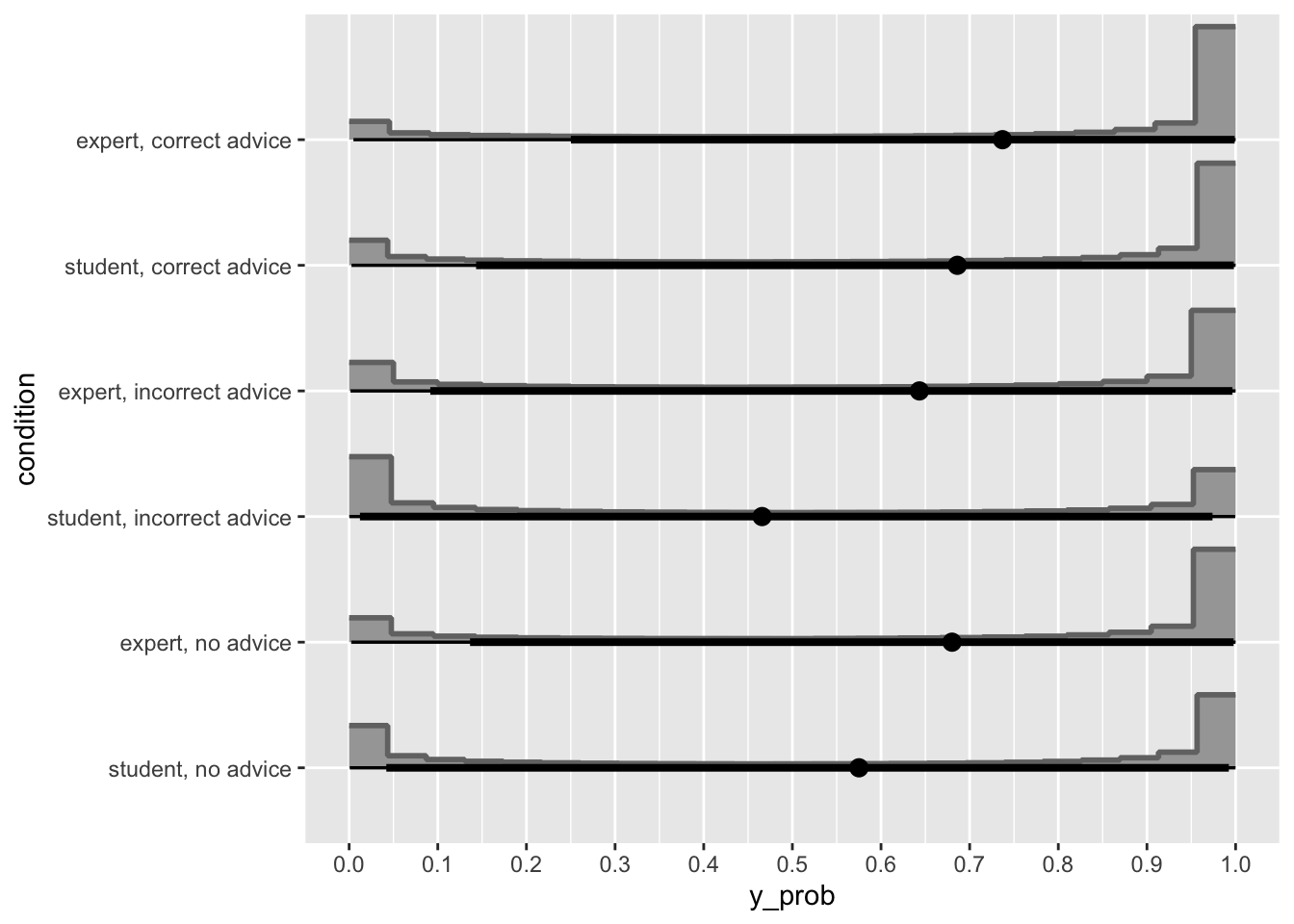
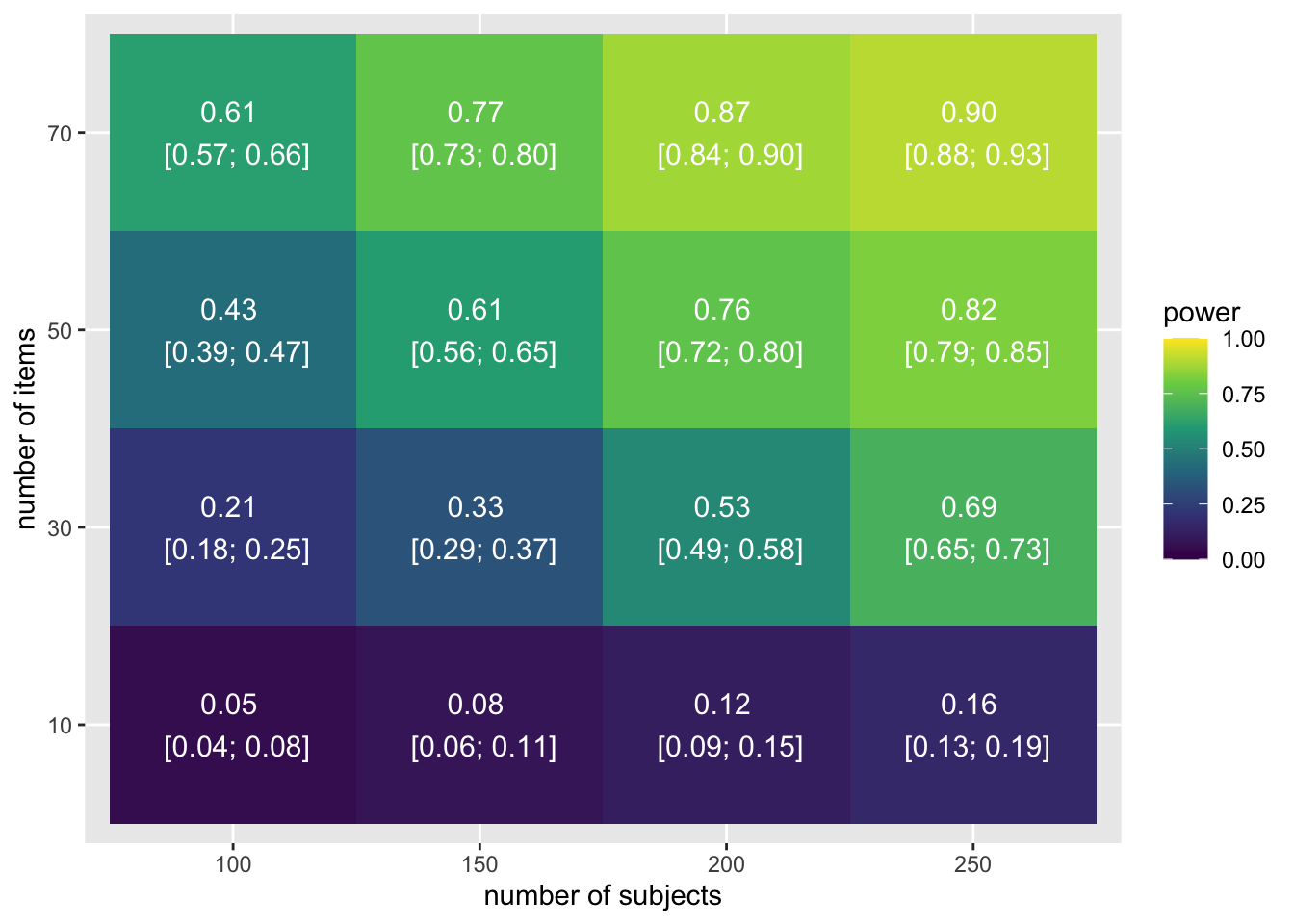
Albers, C., & Lakens, D. (2018). When power analyses based on pilot data are biased:
Inaccurate effect size estimators and follow-up bias.
Journal of Experimental Social Psychology,
74, 187–195.
https://doi.org/10.1016/j.jesp.2017.09.004
Arel-Bundock, V., Greifer, N., & Heiss, A. (Forthcoming). How to interpret statistical models using marginaleffects in R and Python. Journal of Statistical Software.
Arend, M. G., & Schäfer, T. (2019). Statistical power in two-level models:
A tutorial based on
Monte Carlo simulation.
Psychological Methods,
24(1), 1–19.
https://doi.org/10.1037/met0000195
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting
Linear Mixed-Effects Models Using Lme4.
Journal of Statistical Software,
67(1).
https://doi.org/10.18637/jss.v067.i01
Bengtsson, H. (2021). A unifying framework for parallel and distributed processing in r using futures.
The R Journal,
13(2), 208–227.
https://doi.org/10.32614/RJ-2021-048
Benjamin, D. J., Berger, J. O., Johannesson, M., Nosek, B. A., Wagenmakers, E.-J., Berk, R., Bollen, K. A., Brembs, B., Brown, L., Camerer, C., Cesarini, D., Chambers, C. D., Clyde, M., Cook, T. D., De Boeck, P., Dienes, Z., Dreber, A., Easwaran, K., Efferson, C., … Johnson, V. E. (2017). Redefine statistical significance.
Nature Human Behaviour,
2(1), 6–10.
https://doi.org/10.1038/s41562-017-0189-z
Bockting, F., Radev, S. T., & Bürkner, P.-C. (2024). Simulation-based prior knowledge elicitation for parametric
Bayesian models.
Scientific Reports,
14(1), 17330.
https://doi.org/10.1038/s41598-024-68090-7
Bolker, B. M. (2015). Linear and generalized linear mixed models. In G. A. Fox, S. Negrete-Yankelevich, & V. J. Sosa (Eds.),
Ecological Statistics (1st ed., pp. 309–333). Oxford University PressOxford.
https://doi.org/10.1093/acprof:oso/9780199672547.003.0014
Brooks, M., E., Kristensen, K., Benthem, van, J., Magnusson, A., Berg, C., W., Nielsen, A., Skaug, H., J., Mächler, M., & Bolker, B., M. (2017).
glmmTMB Balances Speed and
Flexibility Among Packages for
Zero-inflated Generalized Linear Mixed Modeling.
The R Journal,
9(2), 378.
https://doi.org/10.32614/RJ-2017-066
Brown, V. A. (2021). An
Introduction to
Linear Mixed-Effects Modeling in
R.
Advances in Methods and Practices in Psychological Science,
4(1), 2515245920960351.
https://doi.org/10.1177/2515245920960351
Brysbaert, M., & Stevens, M. (2018). Power
Analysis and
Effect Size in
Mixed Effects Models:
A Tutorial.
Journal of Cognition,
1(1), 9.
https://doi.org/10.5334/joc.10
Bürkner, P.-C. (2017). Brms:
An R Package for
Bayesian Multilevel Models Using Stan.
Journal of Statistical Software,
80, 1–28.
https://doi.org/10.18637/jss.v080.i01
Bürkner, P.-C. (2018). Advanced
Bayesian Multilevel Modeling with the
R Package brms.
The R Journal,
10(1), 395.
https://doi.org/10.32614/RJ-2018-017
Button, K. S., Ioannidis, J. P. A., Mokrysz, C., Nosek, B. A., Flint, J., Robinson, E. S. J., & Munafò, M. R. (2013). Power failure: Why small sample size undermines the reliability of neuroscience.
Nature Reviews Neuroscience,
14(5), 365–376.
https://doi.org/10.1038/nrn3475
Camerer, C. F., Dreber, A., Holzmeister, F., Ho, T.-H., Huber, J., Johannesson, M., Kirchler, M., Nave, G., Nosek, B. A., Pfeiffer, T., Altmejd, A., Buttrick, N., Chan, T., Chen, Y., Forsell, E., Gampa, A., Heikensten, E., Hummer, L., Imai, T., … Wu, H. (2018). Evaluating the replicability of social science experiments in
Nature and
Science between 2010 and 2015.
Nature Human Behaviour,
2(9), 637–644.
https://doi.org/10.1038/s41562-018-0399-z
Chambers, C. D., & Tzavella, L. (2022). The past, present and future of
Registered Reports.
Nature Human Behaviour,
6(1), 29–42.
https://doi.org/10.1038/s41562-021-01193-7
Champely, S. (2020).
Pwr: Basic functions for power analysis.
https://github.com/heliosdrm/pwr
Cohen, J. (1992). A power primer.
Psychological Bulletin,
112(1), 155–159.
https://doi.org/10.1037/0033-2909.112.1.155
Cumming, G. (2014). The
New Statistics:
Why and
How.
Psychological Science,
25(1), 7–29.
https://doi.org/10.1177/0956797613504966
DeBruine, L. (2023).
Faux: Simulation for factorial designs. Zenodo.
https://doi.org/10.5281/zenodo.2669586
DeBruine, L., & Barr, D. J. (2021). Understanding
Mixed-Effects Models Through Data Simulation.
Advances in Methods and Practices in Psychological Science,
4(1), 2515245920965119.
https://doi.org/10.1177/2515245920965119
Deffner, D., Rohrer, J. M., & McElreath, R. (2022). A
Causal Framework for
Cross-Cultural Generalizability.
Advances in Methods and Practices in Psychological Science,
5(3), 251524592211063.
https://doi.org/10.1177/25152459221106366
Dmitrienko, A., & D’Agostino, R. (2013). Traditional multiplicity adjustment methods in clinical trials.
Statistics in Medicine,
32(29), 5172–5218.
https://doi.org/10.1002/sim.5990
Ebersole, C. R., Mathur, M. B., Baranski, E., Bart-Plange, D.-J., Buttrick, N. R., Chartier, C. R., Corker, K. S., Corley, M., Hartshorne, J. K., IJzerman, H., Lazarević, L. B., Rabagliati, H., Ropovik, I., Aczel, B., Aeschbach, L. F., Andrighetto, L., Arnal, J. D., Arrow, H., Babincak, P., … Nosek, B. A. (2020). Many
Labs 5:
Testing Pre-Data-Collection Peer Review as an
Intervention to
Increase Replicability.
Advances in Methods and Practices in Psychological Science,
3(3), 309–331.
https://doi.org/10.1177/2515245920958687
Fahrmeir, L., Kneib, T., Lang, S., & Marx, B. D. (2021).
Regression: Models, Methods and Applications. Springer Berlin Heidelberg.
https://doi.org/10.1007/978-3-662-63882-8
Gelman, A., Vehtari, A., Simpson, D., Margossian, C. C., Carpenter, B., Yao, Y., Kennedy, L., Gabry, J., Bürkner, P.-C., & Modrák, M. (2020).
Bayesian Workflow (arXiv:2011.01808). arXiv.
https://arxiv.org/abs/2011.01808
Gomila, R., & Clark, C. S. (2022). Missing data in experiments:
Challenges and solutions.
Psychological Methods,
27(2), 143–155.
https://doi.org/10.1037/met0000361
Green, P., & MacLeod, C. J. (2016).
SIMR: An
R package for power analysis of generalized linear mixed models by simulation.
Methods in Ecology and Evolution,
7(4), 493–498.
https://doi.org/10.1111/2041-210X.12504
Hallgren, K. A. (2013). Conducting
Simulation Studies in the
R Programming Environment.
Tutorials in Quantitative Methods for Psychology,
9(2), 43–60.
https://doi.org/10.20982/tqmp.09.2.p043
Hartmann, M., Agiashvili, G., Bürkner, P., & Klami, A. (2020). Flexible prior elicitation via the prior predictive distribution. In J. Peters & D. Sontag (Eds.), Proceedings of the 36th conference on uncertainty in artificial intelligence (UAI) (Vol. 124, pp. 1129–1138). PMLR.
Iddi, S., & Donohue, M. C. (2022). Power and
Sample Size for
Longitudinal Models in
R –
The longpower
Package and
Shiny App.
The R Journal,
14(1), 264–282.
https://doi.org/10.32614/RJ-2022-022
Johnson, P. C. D., Barry, S. J. E., Ferguson, H. M., & Müller, P. (2015). Power analysis for generalized linear mixed models in ecology and evolution.
Methods in Ecology and Evolution,
6(2), 133–142.
https://doi.org/10.1111/2041-210X.12306
Kain, M. P., Bolker, B. M., & McCoy, M. W. (2015). A practical guide and power analysis for
GLMMs: Detecting among treatment variation in random effects.
PeerJ,
3, e1226.
https://doi.org/10.7717/peerj.1226
Kelley, K., & Rausch, J. R. (2006). Sample size planning for the standardized mean difference:
Accuracy in parameter estimation via narrow confidence intervals.
Psychological Methods,
11(4), 363–385.
https://doi.org/10.1037/1082-989X.11.4.363
King, M. T. (2011). A point of minimal important difference (
MID): A critique of terminology and methods.
Expert Review of Pharmacoeconomics & Outcomes Research,
11(2), 171–184.
https://doi.org/10.1586/erp.11.9
Kruschke, J. K., & Liddell, T. M. (2018). The
Bayesian New Statistics:
Hypothesis testing, estimation, meta-analysis, and power analysis from a
Bayesian perspective.
Psychonomic Bulletin & Review,
25(1), 178–206.
https://doi.org/10.3758/s13423-016-1221-4
Kumle, L., Võ, M. L.-H., & Draschkow, D. (2021). Estimating power in (generalized) linear mixed models:
An open introduction and tutorial in
R.
Behavior Research Methods,
53(6), 2528–2543.
https://doi.org/10.3758/s13428-021-01546-0
Lafit, G., Adolf, J. K., Dejonckheere, E., Myin-Germeys, I., Viechtbauer, W., & Ceulemans, E. (2021). Selection of the
Number of
Participants in
Intensive Longitudinal Studies:
A User-Friendly Shiny App and
Tutorial for
Performing Power Analysis in
Multilevel Regression Models That Account for
Temporal Dependencies.
Advances in Methods and Practices in Psychological Science,
4(1), 251524592097873.
https://doi.org/10.1177/2515245920978738
Lakens, D. (2022a). Sample
Size Justification.
Collabra: Psychology,
8(1), 33267.
https://doi.org/10.1525/collabra.33267
Lakens, D. (2022b).
Improving Your Statistical Inferences. Zenodo.
https://doi.org/10.5281/ZENODO.6409077
Lakens, D., Adolfi, F. G., Albers, C. J., Anvari, F., Apps, M. A. J., Argamon, S. E., Baguley, T., Becker, R. B., Benning, S. D., Bradford, D. E., Buchanan, E. M., Caldwell, A. R., Van Calster, B., Carlsson, R., Chen, S.-C., Chung, B., Colling, L. J., Collins, G. S., Crook, Z., … Zwaan, R. A. (2018). Justify your alpha.
Nature Human Behaviour,
2(3), 168–171.
https://doi.org/10.1038/s41562-018-0311-x
Lakens, D., & Caldwell, A. R. (2021). Simulation-
Based Power Analysis for
Factorial Analysis of
Variance Designs.
Advances in Methods and Practices in Psychological Science,
4(1), 251524592095150.
https://doi.org/10.1177/2515245920951503
Lakens, D., Scheel, A. M., & Isager, P. M. (2018). Equivalence
Testing for
Psychological Research:
A Tutorial.
Advances in Methods and Practices in Psychological Science,
1(2), 259–269.
https://doi.org/10.1177/2515245918770963
Lane, S. P., & Hennes, E. P. (2018). Power struggles:
Estimating sample size for multilevel relationships research.
Journal of Social and Personal Relationships,
35(1), 7–31.
https://doi.org/10.1177/0265407517710342
LeBeau, B. (2019).
Power Analysis by Simulation using R and simglm.
https://doi.org/10.17077/f7kk-6w7f
Lee, S., Sriutaisuk, S., & Kim, H. (2020). Using the
Tidyverse Package in
R for
Simulation Studies in
SEM.
Structural Equation Modeling: A Multidisciplinary Journal,
27(3), 468–482.
https://doi.org/10.1080/10705511.2019.1644515
Little, R. J. A., & Rubin, D. B. (2014). Statistical Analysis with Missing Data (2nd ed). Wiley.
Lundberg, I., Johnson, R., & Stewart, B. M. (2021). What
Is Your Estimand?
Defining the
Target Quantity Connects Statistical Evidence to
Theory.
American Sociological Review,
86(3), 532–565.
https://doi.org/10.1177/00031224211004187
Magnusson, K., Andersson, G., & Carlbring, P. (2018). The consequences of ignoring therapist effects in trials with longitudinal data:
A simulation study.
Journal of Consulting and Clinical Psychology,
86(9), 711–725.
https://doi.org/10.1037/ccp0000333
Martin, J. G. A., Nussey, D. H., Wilson, A. J., & Réale, D. (2011). Measuring individual differences in reaction norms in field and experimental studies: A power analysis of random regression models.
Methods in Ecology and Evolution,
2(4), 362–374.
https://doi.org/10.1111/j.2041-210X.2010.00084.x
Matuschek, H., Kliegl, R., Vasishth, S., Baayen, H., & Bates, D. (2017). Balancing
Type I error and power in linear mixed models.
Journal of Memory and Language,
94, 305–315.
https://doi.org/10.1016/j.jml.2017.01.001
Maxwell, S. E., Kelley, K., & Rausch, J. R. (2008). Sample
Size Planning for
Statistical Power and
Accuracy in
Parameter Estimation.
Annual Review of Psychology,
59(1), 537–563.
https://doi.org/10.1146/annurev.psych.59.103006.093735
McElreath, R. (2020).
Statistical Rethinking: A Bayesian Course with Examples in R and Stan (2nd ed.).
Chapman and Hall/CRC.
https://doi.org/10.1201/9780429029608
Meteyard, L., & Davies, R. A. I. (2020). Best practice guidance for linear mixed-effects models in psychological science.
Journal of Memory and Language,
112, 104092.
https://doi.org/10.1016/j.jml.2020.104092
Mikkola, P., Martin, O. A., Chandramouli, S., Hartmann, M., Abril Pla, O., Thomas, O., Pesonen, H., Corander, J., Vehtari, A., Kaski, S., Bürkner, P.-C., & Klami, A. (2023). Prior
Knowledge Elicitation:
The Past,
Present, and
Future.
Bayesian Analysis,
-1(-1).
https://doi.org/10.1214/23-BA1381
Murayama, K., Usami, S., & Sakaki, M. (2022). Summary-statistics-based power analysis:
A new and practical method to determine sample size for mixed-effects modeling.
Psychological Methods.
https://doi.org/10.1037/met0000330
Preacher, K. J., Curran, P. J., & Bauer, D. J. (2006). Computational
Tools for
Probing Interactions in
Multiple Linear Regression,
Multilevel Modeling, and
Latent Curve Analysis.
Journal of Educational and Behavioral Statistics,
31(4), 437–448.
https://doi.org/10.3102/10769986031004437
R Core Team. (2024).
R: A language and environment for statistical computing. R Foundation for Statistical Computing.
https://www.R-project.org/
Riesthuis, P. (2024). Simulation-
Based Power Analyses for the
Smallest Effect Size of
Interest:
A Confidence-Interval Approach for
Minimum-Effect and
Equivalence Testing.
Advances in Methods and Practices in Psychological Science,
7(2), 25152459241240722.
https://doi.org/10.1177/25152459241240722
Schad, D. J., Betancourt, M., & Vasishth, S. (2021). Toward a principled
Bayesian workflow in cognitive science.
Psychological Methods,
26(1), 103–126.
https://doi.org/10.1037/met0000275
Schad, D. J., Vasishth, S., Hohenstein, S., & Kliegl, R. (2020). How to capitalize on a priori contrasts in linear (mixed) models:
A tutorial.
Journal of Memory and Language,
110, 104038.
https://doi.org/10.1016/j.jml.2019.104038
Stefan, A. M., Evans, N. J., & Wagenmakers, E.-J. (2022). Practical challenges and methodological flexibility in prior elicitation.
Psychological Methods,
27(2), 177–197.
https://doi.org/10.1037/met0000354
Uygun Tunç, D., Tunç, M. N., & Lakens, D. (2023). The epistemic and pragmatic function of dichotomous claims based on statistical hypothesis tests.
Theory & Psychology,
33(3), 403–423.
https://doi.org/10.1177/09593543231160112
Vaughan, D., & Dancho, M. (2022).
Furrr: Apply mapping functions in parallel using futures.
https://CRAN.R-project.org/package=furrr
Watson, S. I. (2023).
Generalised Linear Mixed Model Specification, Analysis, Fitting, and Optimal Design in R with the glmmr Packages. arXiv.
https://doi.org/10.48550/ARXIV.2303.12657
Westfall, J., Kenny, D. A., & Judd, C. M. (2014). Statistical power and optimal design in experiments in which samples of participants respond to samples of stimuli.
Journal of Experimental Psychology: General,
143, 2020–2045.
https://doi.org/10.1037/xge0000014
Wickham, H., Averick, M., Bryan, J., Chang, W., McGowan, L., François, R., Grolemund, G., Hayes, A., Henry, L., Hester, J., Kuhn, M., Pedersen, T., Miller, E., Bache, S., Müller, K., Ooms, J., Robinson, D., Seidel, D., Spinu, V., … Yutani, H. (2019). Welcome to the
Tidyverse.
Journal of Open Source Software,
4(43), 1686.
https://doi.org/10.21105/joss.01686
Wickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd edition). O’Reilly.
Yarkoni, T. (2022). The generalizability crisis.
Behavioral and Brain Sciences,
45, e1.
https://doi.org/10.1017/S0140525X20001685
Yu, M. (2019).
Pass.lme: Power and Sample Size for Linear Mixed Effect Models (p. 0.9.0). Comprehensive R Archive Network.
https://doi.org/10.32614/CRAN.package.pass.lme
Zhang, Z., & Yuan, K.-H. (2018).
Practical statistical power analysis using Webpower and R. ISDSA Press.
https://doi.org/10.35566/power
Zimmer, F., Henninger, M., & Debelak, R. (2023). Sample size planning for complex study designs:
A tutorial for the mlpwr package.
Behavior Research Methods.
https://doi.org/10.3758/s13428-023-02269-0